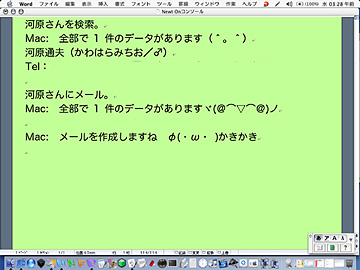
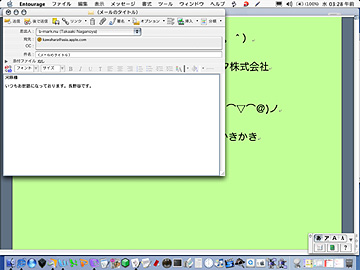
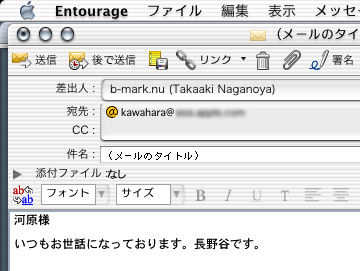
翻訳対象の文と、翻訳先の言語コード(2文字コード)を指定すると、macOS内のサービスを呼び出して翻訳して返します。
翻訳を司るTranslation.frameworkはAppleScriptObjCから呼び出せないため、Swiftを介して呼び出してみました。
実際に、AppleScriptObjCから呼び出すことも試みてみたのですが、結局できず……逆に、この手の処理はAppleScriptから呼び出せると有用性が高いもののはずなので、呼び出せないことに納得が行かず、いろんな方法を試行。
実行処理を考えると、AppleScriptバンドル書類内にSwiftからビルドした実行バイナリを入れて呼び出す方が速くてよいのですが、実行環境の多さを考慮してテキスト形式のSwiftを組み込むようにしてみました。
| AppleScript名:翻訳テスト_v5.scptd |
| — – Created by: Takaaki Naganoya – Created on: 2026/03/25 — – Copyright © 2026 Piyomaru Software, All Rights Reserved — set targetLang to "ja" set textList to {"Stay hungry, stay foolish.", "Innovation distinguishes between a leader and a follower."} set sRes to translateList(targetLang, textList) of me –> (* "飢え続け、愚かであり続けてください。 イノベーションはリーダーとフォロワーを区別します。" *) on translateList(targetLang, textList) — 引数の組み立て set argString to targetLang repeat with aText in textList set argString to argString & " " & (quoted form of aText) end repeat — Swiftソースコード — 実行速度と安定性を考慮し、RunLoopを使用して非同期完了を待機します set shellCmd to "swift – " & argString & " <<’EOF’ import Foundation import Translation import NaturalLanguage let args = CommandLine.arguments let targetLanguage = args[1] let recognizer = NLLanguageRecognizer() let source = Locale.Language(identifier: identifiedLanguage) // 翻訳実行フラグ Task { do { let requests = textsToTranslate.map { TranslationSession.Request(sourceText: $0) } let response = try await session.translations(from: requests) for result in response { print(result.targetText) } } catch { fputs(\"Error: \\(error.localizedDescription)\\n\", stderr) } isFinished = true } // 非同期処理が完了するまでRunLoopを回して待機する } EOF" try — do shell script は標準出力が返るまで待機します set translatedResults to do shell script shellCmd return translatedResults on error errMsg error "翻訳エラー" & return & errMsg end try end translateList |
| AppleScript名:翻訳言語コードを取得.scpt |
| — – Created by: Takaaki Naganoya – Created on: 2026/03/25 — – Copyright © 2026 Piyomaru Software, All Rights Reserved — set langList to returnLangCodes() of me –> {"ar", "de", "en", "es", "fr", "hi", "id", "it", "ja", "ko", "nl", "pl", "pt", "ru", "th", "tr", "uk", "vi", "zh"} on returnLangCodes() set shellCmd to "swift – <<’EOF’ import Foundation import Translation Task { let supportedLanguages = await availability.supportedLanguages // languageCode(ja, enなど)のみを抽出し、重複を除いてソート for code in codes { } exit(0) } RunLoop.main.run(until: Date(timeIntervalSinceNow: 5)) try — 言語コードを改行区切りで取得 set supportedCodes to do shell script shellCmd — リスト形式に変換 set oldDelims to AppleScript’s text item delimiters set AppleScript’s text item delimiters to string id 13 set codeList to text items of supportedCodes set AppleScript’s text item delimiters to oldDelims — 結果を表示 if (count of codeList) > 0 then return codeList else error "言語コードが見つかりませんでした。" end if set the clipboard to (codeList as string) on error errMsg error "取得エラー" & return & errMsg end try end returnLangCodes |