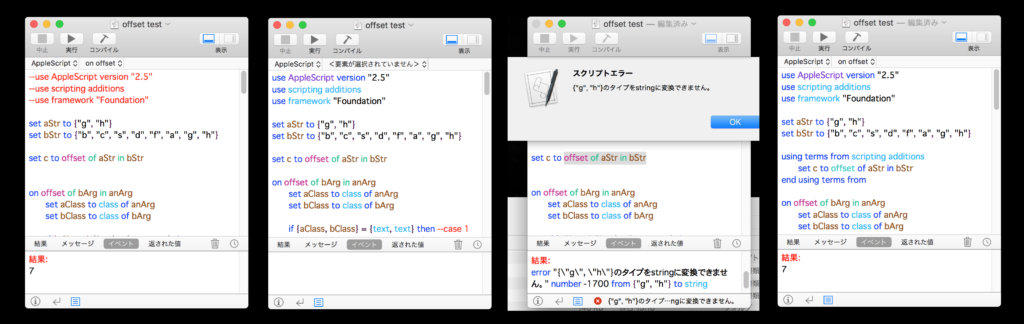
簡易的な日本語テキストのParse(辞書なし)を行うAppleScriptです。
英語などの言語では、文章中の各単語の間にスペース(” “)を入れるようになっており、
My name is Takaaki Naganoya.
文章を単語ごとに分割することがきわめて容易です。
words of "My name is Takaaki Naganoya."
--> {"My", "name", "is", "Takaaki", "Naganoya"}
一方、日本語の文章において単語は続けて記述するため、
私の名前は長野谷です。
これを単語ごとに切り分けるのは大変です。そのため、単語の辞書を手掛かりに文章中の単語を切り分けるのが普通です。
辞書を使って単語単位の切り分けを行う日本語形態素解析器
日本語テキストを単語(形態素)ごとに区分けするソフトウェアは日本語形態素解析器と呼ばれます。Chasen、Juman、MeCabなどが有名です。形態素解析のための巨大な辞書を用いて、地名ぐらいの固有名詞なら問題なくParseできることが普通です。各単語がどの品詞なのか、活用形はどうなっているかといった文法的な情報も管理しています。
たとえば、ApitoreのREST API経由でKuromojiを呼び出して形態素解析を行うと、
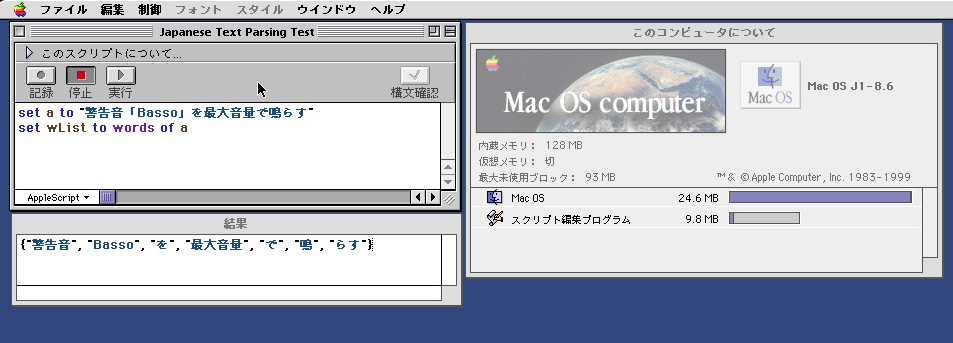
"警告音「Basso」を最大音量で鳴らす"
-->{{startTime:"1538006762864", tokens:{{partOfSpeechLevel1:"名詞", baseForm:"警告", pronunciation:"ケイコク", position:0, partOfSpeechLevel3:"*", reading:"ケイコク", surface:"警告", known:true, allFeatures:"名詞,サ変接続,*,*,*,*,警告,ケイコク,ケイコク", conjugationType:"*", partOfSpeechLevel2:"サ変接続", conjugationForm:"*", allFeaturesArray:{"名詞", "サ変接続", "*", "*", "*", "*", "警告", "ケイコク", "ケイコク"}, partOfSpeechLevel4:"*"}, {partOfSpeechLevel1:"名詞", baseForm:"音", pronunciation:"オン", position:2, partOfSpeechLevel3:"一般", reading:"オン", surface:"音", known:true, allFeatures:"名詞,接尾,一般,*,*,*,音,オン,オン", conjugationType:"*", partOfSpeechLevel2:"接尾", conjugationForm:"*", allFeaturesArray:{"名詞", "接尾", "一般", "*", "*", "*", "音", "オン", "オン"}, partOfSpeechLevel4:"*"}, {partOfSpeechLevel1:"記号", baseForm:"「", pronunciation:"「", position:3, partOfSpeechLevel3:"*", reading:"「", surface:"「", known:true, allFeatures:"記号,括弧開,*,*,*,*,「,「,「", conjugationType:"*", partOfSpeechLevel2:"括弧開", conjugationForm:"*", allFeaturesArray:{"記号", "括弧開", "*", "*", "*", "*", "「", "「", "「"}, partOfSpeechLevel4:"*"}, {partOfSpeechLevel1:"名詞", baseForm:"Basso", pronunciation:"バッソ", position:4, partOfSpeechLevel3:"一般", reading:"バッソ", surface:"Basso", known:true, allFeatures:"名詞,固有名詞,一般,*,*,*,Basso,バッソ,バッソ", conjugationType:"*", partOfSpeechLevel2:"固有名詞", conjugationForm:"*", allFeaturesArray:{"名詞", "固有名詞", "一般", "*", "*", "*", "Basso", "バッソ", "バッソ"}, partOfSpeechLevel4:"*"}, {partOfSpeechLevel1:"記号", baseForm:"」", pronunciation:"」", position:9, partOfSpeechLevel3:"*", reading:"」", surface:"」", known:true, allFeatures:"記号,括弧閉,*,*,*,*,」,」,」", conjugationType:"*", partOfSpeechLevel2:"括弧閉", conjugationForm:"*", allFeaturesArray:{"記号", "括弧閉", "*", "*", "*", "*", "」", "」", "」"}, partOfSpeechLevel4:"*"}, {partOfSpeechLevel1:"助詞", baseForm:"を", pronunciation:"ヲ", position:10, partOfSpeechLevel3:"一般", reading:"ヲ", surface:"を", known:true, allFeatures:"助詞,格助詞,一般,*,*,*,を,ヲ,ヲ", conjugationType:"*", partOfSpeechLevel2:"格助詞", conjugationForm:"*", allFeaturesArray:{"助詞", "格助詞", "一般", "*", "*", "*", "を", "ヲ", "ヲ"}, partOfSpeechLevel4:"*"}, {partOfSpeechLevel1:"名詞", baseForm:"最大", pronunciation:"サイダイ", position:11, partOfSpeechLevel3:"*", reading:"サイダイ", surface:"最大", known:true, allFeatures:"名詞,一般,*,*,*,*,最大,サイダイ,サイダイ", conjugationType:"*", partOfSpeechLevel2:"一般", conjugationForm:"*", allFeaturesArray:{"名詞", "一般", "*", "*", "*", "*", "最大", "サイダイ", "サイダイ"}, partOfSpeechLevel4:"*"}, {partOfSpeechLevel1:"名詞", baseForm:"音量", pronunciation:"オンリョー", position:13, partOfSpeechLevel3:"*", reading:"オンリョウ", surface:"音量", known:true, allFeatures:"名詞,一般,*,*,*,*,音量,オンリョウ,オンリョー", conjugationType:"*", partOfSpeechLevel2:"一般", conjugationForm:"*", allFeaturesArray:{"名詞", "一般", "*", "*", "*", "*", "音量", "オンリョウ", "オンリョー"}, partOfSpeechLevel4:"*"}, {partOfSpeechLevel1:"助詞", baseForm:"で", pronunciation:"デ", position:15, partOfSpeechLevel3:"一般", reading:"デ", surface:"で", known:true, allFeatures:"助詞,格助詞,一般,*,*,*,で,デ,デ", conjugationType:"*", partOfSpeechLevel2:"格助詞", conjugationForm:"*", allFeaturesArray:{"助詞", "格助詞", "一般", "*", "*", "*", "で", "デ", "デ"}, partOfSpeechLevel4:"*"}, {partOfSpeechLevel1:"動詞", baseForm:"鳴らす", pronunciation:"ナラス", position:16, partOfSpeechLevel3:"*", reading:"ナラス", surface:"鳴らす", known:true, allFeatures:"動詞,自立,*,*,五段・サ行,基本形,鳴らす,ナラス,ナラス", conjugationType:"五段・サ行", partOfSpeechLevel2:"自立", conjugationForm:"基本形", allFeaturesArray:{"動詞", "自立", "*", "*", "五段・サ行", "基本形", "鳴らす", "ナラス", "ナラス"}, partOfSpeechLevel4:"*"}}, endTime:"1538006762864", |log|:"", processTime:"0"}}
のようになります。これらのデータのうち、surface項目を抽出すると、
--> {"警告", "音", "「", "Basso", "」", "を", "最大", "音量", "で", "鳴らす", "。"}
となります。
辞書を使わずにトリッキーな方法で単語単位の切り分けを行う日本語パーサー
一方で、これらの日本語形態素解析器ほどの大規模なデータや機能が必要ない場合もあります。形態素解析のための辞書を持たず、単にそれっぽく単語ごとに区切ることができればよいという、「割り切った用途」に用いるもので、便宜上「日本語パーサー」と呼びます。単語っぽいものに分割することが目的であり、品詞のデータなどは取得できないのが普通です。
この種類のソフトウェアは、工藤 拓さんのTinySegmenterがあり、これをObjective-Cに移植したSuper compact Japanese tokenizer 「Tiny Segmenter」をCocoa Framework化してAppleScriptから呼び出し、テストしています。正規表現を用いて助詞などをピックアップして、それを手掛かりに単語切り分けを行うもので、そのサイズからは想像できないぐらいまっとうに単語に切り分けてくれます。
このTiny Segmenter(Objective-C版)をコマンド解釈用に使ってみたのですが、
--> {"警告音", "「Basso", "」", "を", "最大", "音量", "で", "鳴ら", "す"}
記号などがきちんと分離されなかったため、いまひとつ。自分でコマンド解釈用のParserを作ってみることにしました。
words ofの不完全さを補う簡易日本語パーサーeasyJParse
AppleScriptの「words of」は、前述のように英文であればスペースを区切り子として、文章の単語への分解を行ってくれます。
一方、日本語テキストに対して「words of」で単語分解処理を行うと、ながらく「文字種別の切り替え箇所で区切る」という気の狂ったような使えない処理が行われていました。その無意味さと使えなさをAppleのエンジニアにことあるごとに説明してきたのですが、一向に理解されず、相手にされてきませんでした。
# 冗談抜きで、Appleのエンジニアとは「戦いの歴史」しかありません。そして、そうして戦って勝ち取っていかないと機能の改善もバグの修正も何もないのであります(本当)
風向きが変わってきたのは、OS X 10.6のころ。このころから日本語テキストのwords ofの実行結果が形態素解析を行なっているような気がする動作を行うようになっており、何かに使えるような気がするものの……
words of "警告音「Basso」を最大音量で鳴らす。"
--> {"警告", "音", "Basso", "を", "最大", "音量", "で", "鳴らす"}
なぜか記号類などをすべて無視してしまうので、いまひとつ実用性がありませんでした。
そこで、基本的にはこの「words of」の演算結果を活かしつつ、オリジナルの文章と比較を行なって、欠損した記号類を補うことで簡易日本語parserとして利用できるのでは? と考えました。
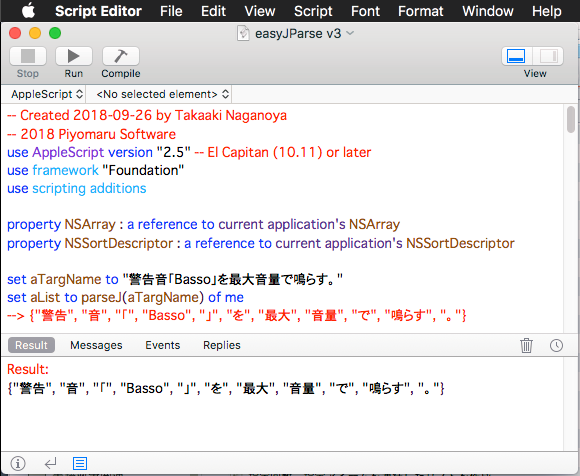
set aTargName to "警告音「Basso」を最大音量で鳴らす。"
set aList to parseJ(aTargName) of me
--> {"警告", "音", "「", "Basso", "」", "を", "最大", "音量", "で", "鳴らす", "。"}
実際に作ってテストしてみたところ、自分が必要なコマンド解析ぐらいの目的には十分に使えることがわかりました。むしろ、単語切り分けについてはKuromojiと同じ結果が得られています。
しかも、辞書を持たないためコンパクトであり、実行速度もたいへんに高速で、このeasyJParseを組み込んだプログラムはREST APIの日本語形態素解析器を呼んだバージョンよりも明らかに高速化され、ネットワーク接続のない環境でも実行可能になりました。いいことづくめです。
easyJParseの制約事項
なお、easyJParseはすでに文章単位で分割されたテキストをコマンド解釈用に分解するため「だけ」に作ったものであり、長文を文章ごとに分割する機能は持っていません。別のプログラムやルーチンで文章ごとに分割してからeasyJParseで処理してください。
easyJParseは、日本語ユーザー環境における日本語テキストに対する「words of」の演算結果を利用しており、言語環境が日本語に設定していない環境で同様に演算できることは保証していません。
→ 一応、英語ユーザー環境で実行してみたら期待どおりの動作を行いました
当然のことながら、macOS専用です。一部Cocoaの機能を呼び出しているため、macOS 10.10以降で動きます(10.10では動作確認していませんけれども)。
| AppleScript名:easyJParse v3 |
— Created 2018-09-26 by Takaaki Naganoya
— 2018 Piyomaru Software
use AppleScript version "2.5" — El Capitan (10.11) or later
use framework "Foundation"
use scripting additions
property NSArray : a reference to current application’s NSArray
property NSSortDescriptor : a reference to current application’s NSSortDescriptor
set aTargName to "警告音「Basso」を最大音量で鳴らす。"
set aList to parseJ(aTargName) of me
–> {"警告", "音", "「", "Basso", "」", "を", "最大", "音量", "で", "鳴らす", "。"}
–set aTargName to "JPEGファイルを50%にリサイズして、デスクトップの「AAA」フォルダに出力"
–set aList to parseJ(aTargName) of me
–> {"JPEG", "ファイル", "を", "50", "%", "に", "リサイズ", "し", "て", "、", "デスクトップ", "の", "「", "AAA", "」", "フォルダ", "に", "出力"}
on parseJ(aTargStr as string)
copy aTargStr to tStr
set cList to characters of tStr
set wList to words of tStr
set cLen to length of cList
set w2List to {}
set w3List to {}
set aCount to 0
set lastPos to 0
repeat with i in wList
set j to contents of i
set anOffset to offset of j in tStr
if anOffset is not equal to 1 then
set aChar to character (lastPos + 1) of aTargStr
set the end of w3List to {wordList:aChar, characterList:{aChar}, startPos:(lastPos + 1), endPos:(lastPos + 1)}
end if
set aLen to length of j
set w2List to w2List & (characters of j)
set startPointer to (anOffset + aCount)
set endPointer to (anOffset + aCount + aLen – 1)
set the end of w3List to {wordList:j, characterList:(characters of j), startPos:startPointer, endPos:endPointer}
set trimStart to (anOffset + aLen)
if trimStart > (length of tStr) then
set trimStart to 1
end if
set tStr to text trimStart thru -1 of tStr
set aCount to aCount + anOffset + aLen – 1
copy endPointer to lastPos
end repeat
–句読点など。文末の処理
if endPointer is not equal to cLen then
set the end of w3List to {wordList:tStr, characterList:(characters of tStr), startPos:(lastPos + aCount), endPos:aLen}
end if
set bArray to sortRecListByLabel((w3List), "startPos", true) of me
set cArray to (bArray’s valueForKeyPath:"wordList") as list
return cArray
end parseJ
–リストに入れたレコードを、指定の属性ラベルの値でソート
on sortRecListByLabel(aRecList as list, aLabelStr as string, ascendF as boolean)
set aArray to NSArray’s arrayWithArray:aRecList
set sortDesc to NSSortDescriptor’s alloc()’s initWithKey:aLabelStr ascending:ascendF
set sortDescArray to NSArray’s arrayWithObjects:sortDesc
set sortedArray to aArray’s sortedArrayUsingDescriptors:sortDescArray
return sortedArray
end sortRecListByLabel
|
|
★Click Here to Open This Script
|