




UniversalDetector.frameworkを呼び出して指定のテキストファイルの文字コードを判定するAppleScriptです。
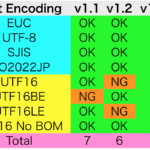
日本語のテキストで実験してみたところ、UTF-16系以外は正常に判定できています。日本語以外の言語を対象にした場合には使い手がありそうですが、日本語を対象にした場合には、「文字エンコーディングを自動判別してファイル読み込み v1.2.1」のほうが便利です。
–> UniversalDetector.framework
| AppleScript名:UniversalDetectorで文字コード判定 |
| — Created 2015-10-03 by Takaaki Naganoya — 2015 Piyomaru Software use AppleScript version "2.5" use scripting additions use framework "Foundation" use framework "UniversalDetector" –https://github.com/JanX2/UniversalDetector set aPath to (POSIX path of (choose file)) set aStr to current application’s NSString’s stringWithString:aPath set aDetector to current application’s UniversalDetector’s new() aDetector’s analyzeContentsOfFile:aStr set aStr to current application’s NSString’s localizedNameOfStringEncoding:(aDetector’s encoding()) –> (NSString) "日本語(EUC)" –> (NSString) "日本語(ISO 2022-JP)" –> (NSString) "日本語(Shift JIS)" –> (NSString) "Unicode(UTF-8)" –> (NSString) "キリル文字(Windows)" –NG。本当はUTF-16 no BOM –> (NSString) "中国語(GB 18030)"–NG。本当はUTF-16BE –> (NSString) "Unicode(UTF-16)" set bStr to aDetector’s MIMECharset() –> (NSString) "EUC-JP" –> (NSString) "ISO-2022-JP" –> (NSString) "Shift_JIS" –> (NSString) "UTF-8" –> (NSString) "windows-1251"–NG –> (NSString) "gb18030"–NG –> (NSString) "UTF-16" set aNum to (aDetector’s confidence()) * 100 –> 100.0–"EUC-JP" –> 100.0–"ISO-2022-JP" –> 100.0–"Shift_JIS" –> 100.0–"UTF-8" –> 5.271286144853–UTF-16 no BOM –> 100.0–NGだが100%といっている –> 100.0– "UTF-16" return {aStr as string, bStr as string, aNum} |


(Visited 536 times, 1 visits today)