| AppleScript名:PDFのサイズをpointで取得 |
| — Created 2017-06-16 00:44:52 +0900 by Takaaki Naganoya — 2017 Piyomaru Software use AppleScript version "2.4" use scripting additions use framework "Foundation" use framework "Quartz" use framework "AppKit" set aHFSPath to (choose file of type {"com.adobe.pdf"} with prompt "Select PDF") set aPOSIX to POSIX path of aHFSPath set aURL to (current application’s |NSURL|’s fileURLWithPath:aPOSIX) set aPDFdoc to current application’s PDFDocument’s alloc()’s initWithURL:aURL set pCount to aPDFdoc’s pageCount() set aPage to aPDFdoc’s pageAtIndex:0 –PDFのサイズを取得する(単位:Point) set aBounds to aPage’s boundsForBox:(current application’s kPDFDisplayBoxMediaBox) set aSize to |size| of aBounds –> {width:595.28, height:841.89} |
カテゴリー: PDF
指定PDFの全ページからリンクアノテーションのURLを取得(http)v2
指定のPDFの全ページを走査してリンクアノテーションのURLのうちURL Schemeが”http”のものを抽出し、”http://piyocast.com/as/archives/” を含むURLを取得するAppleScriptです。
macOS 10.13以降でも動作するようにしてあります。電子書籍のPDFから本Blogへのリンクを張ってある箇所を検出するために作成したものです。
| AppleScript名:指定PDFの全ページからリンクアノテーションのURLを取得(http)v2 |
| — Created 2017-06-08 by Takaaki Naganoya — Modified 2018-02-14 by Takaaki Naganoya — 2017 Piyomaru Software use AppleScript version "2.5" use scripting additions use framework "Foundation" use framework "Quartz" property |NSURL| : a reference to current application’s |NSURL| property PDFDocument : a reference to current application’s PDFDocument set aPOSIX to POSIX path of (choose file of type {"com.adobe.pdf"} with prompt "Choose a PDF with Annotation") set linkList to getLinkURLFromPDF(aPOSIX, "http", "http://piyocast.com/as/archives/") of me –> {{pageNum:39, linkURL:"http://piyocast.com/as/archives/69"},….} on getLinkURLFromPDF(aPOSIX, urlScheme, condURL) set v2 to system attribute "sys2" –> macOS 10.12 =12 set aURL to (|NSURL|’s fileURLWithPath:aPOSIX) set aPDFdoc to PDFDocument’s alloc()’s initWithURL:aURL set pCount to aPDFdoc’s pageCount() set outList to {} –PDFのページでループ repeat with ii from 0 to (pCount – 1) set tmpPage to (aPDFdoc’s pageAtIndex:ii) set anoList to (tmpPage’s annotations()) as list if anoList is not equal to {missing value} then –指定PDF中にAnotationが存在した –対象PDFPage内で検出されたAnnotationでループ repeat with i in anoList if v2 < 13 then –to macOS Sierra set aType to (i’s type()) as string else –macOS High Sierra or later set aType to (i’s |Type|()) as string end if — if aType = "Link" then set tmpURL to i’s |URL|() if tmpURL is not equal to missing value then set tmpScheme to (tmpURL’s |scheme|()) as string if tmpScheme = urlScheme then set urlStr to (tmpURL’s absoluteString()) as string if (urlStr contains condURL) then set the end of outList to {pageNum:(ii + 1), linkURL:urlStr} end if end if end if end if end repeat end if end repeat return outList end getLinkURLFromPDF |
指定PDFの全ページからリンクアノテーションのURLを取得(applescript) v2
指定のPDFの全ページを走査してリンクアノテーションのURLのうちURL Schemeが”applescript”のものを抽出して、Link Scriptの内容を取得するAppleScriptです。
macOS 10.13以降でも動作するようにしてあります。
| AppleScript名:指定PDFの全ページからリンクアノテーションのURLを取得(applescript) v2 |
| — Created 2017-06-08 by Takaaki Naganoya — Modified 2018-02-14 by Takaaki Naganoya — 2017 Piyomaru Software use AppleScript version "2.5" use scripting additions use framework "Foundation" use framework "Quartz" property |NSURL| : a reference to current application’s |NSURL| property NSString : a reference to current application’s NSString property PDFDocument : a reference to current application’s PDFDocument property NSMutableDictionary : a reference to current application’s NSMutableDictionary property NSUTF8StringEncoding : a reference to current application’s NSUTF8StringEncoding set aPOSIX to POSIX path of (choose file of type {"com.adobe.pdf"} with prompt "Choose a PDF with Annotation") set linkList to getLinkURLFromPDF(aPOSIX, "applescript") of me –> {{pageNum:95, linkScript:"set aStr to \"ぴよまるソフトウェア\" set aPath to choose file name……}} on getLinkURLFromPDF(aPOSIX, urlScheme) set v2 to system attribute "sys2" –> macOS 10.12 =12 set aURL to (|NSURL|’s fileURLWithPath:aPOSIX) set aPDFdoc to PDFDocument’s alloc()’s initWithURL:aURL set pCount to aPDFdoc’s pageCount() set outList to {} –PDFのページでループ repeat with ii from 0 to (pCount – 1) set tmpPage to (aPDFdoc’s pageAtIndex:ii) set anoList to (tmpPage’s annotations()) as list if anoList is not equal to {missing value} then –指定PDF中にAnotationが存在した –対象PDFPage内で検出されたAnnotationでループ repeat with i in anoList if v2 < 13 then –to macOS Sierra set aType to (i’s type()) as string else –macOS High Sierra or later set aType to (i’s |Type|()) as string end if — if aType = "Link" then set tmpURL to i’s |URL|() if tmpURL is not equal to missing value then set tmpScheme to (tmpURL’s |scheme|()) as string if tmpScheme = urlScheme then set urlStr to (tmpURL’s absoluteString()) as string set urlRec to parseQueryDictFromURLString(urlStr) of me set tmpScript to (urlRec’s |script|) as string set the end of outList to {pageNum:(ii + 1), linkScript:tmpScript} end if end if end if end repeat end if end repeat return outList end getLinkURLFromPDF on parseQueryDictFromURLString(aURLStr as string) if aURLStr = "" then error "No URL String" set aURL to |NSURL|’s URLWithString:aURLStr set aQuery to aURL’s query() –Get Query string part from URL if aQuery’s |length|() = 0 then return false set aDict to NSMutableDictionary’s alloc()’s init() set aParamList to (aQuery’s componentsSeparatedByString:"&") as list repeat with i in aParamList set j to contents of i if length of j > 0 then set tmpStr to (NSString’s stringWithString:j) set eList to (tmpStr’s componentsSeparatedByString:"=") set anElement to (eList’s firstObject()’s stringByReplacingPercentEscapesUsingEncoding:(NSUTF8StringEncoding)) set aValStr to (eList’s lastObject()’s stringByReplacingPercentEscapesUsingEncoding:(NSUTF8StringEncoding)) (aDict’s setObject:aValStr forKey:anElement) end if end repeat return aDict end parseQueryDictFromURLString |
MacDownで編集中のMarkDown書類で見出しが見出し落ちしていないかチェック
MacDownで編集中のMarkdown書類をいったんデスクトップにPDF書き出しして、見出しがページ末尾に位置していないか(見出し落ち)をチェックするAppleScriptです。
MacDownのAppleScript対応機能が少ないので、ほとんどAppleScriptだけで処理しています。Cocoaの機能を呼べるようになったので、とくに問題ありません。
MacDownで編集中の最前面のMarkdown書類からパスを取得し、AppleScriptで直接ファイルから内容を読み込み、正規表現で見出し一覧を取得します。
MacDownからGUI Scripting経由でメニューをコントロールしてPDF書き出しを行い、ページ単位でPDFからテキストを抽出。不要な空白文字列などを削除。
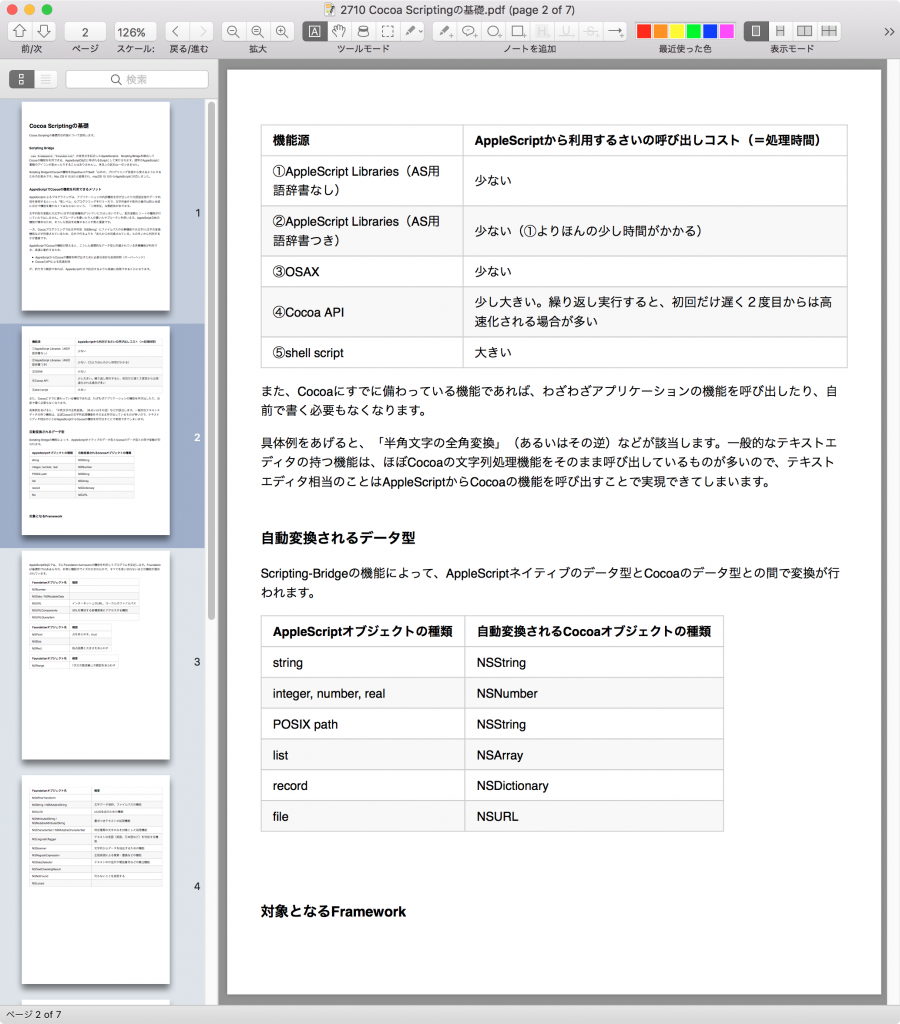
▲いわゆる「見出し落ち」の状態。ページ末尾に見出し項目が存在している
各ページのテキストが見出しの内容で終了していれば、結果出力用の変数midashiOchiListに{ページ数, 見出し名称} を追加して出力します。
–> {{2, “対象となるFramework”}}
| AppleScript名:MacDownで編集中のMarkDown書類で見出しが見出し落ちしていないかチェック |
| — Created 2017-08-12 by Takaaki Naganoya — 2017 Piyomaru Software use AppleScript version "2.5" use scripting additions use framework "Foundation" use framework "Quartz" property NSString : a reference to current application’s NSString property NSCharacterSet : a reference to current application’s NSCharacterSet property NSRegularExpression : a reference to current application’s NSRegularExpression property NSRegularExpressionAnchorsMatchLines : a reference to current application’s NSRegularExpressionAnchorsMatchLines property NSRegularExpressionDotMatchesLineSeparators : a reference to current application’s NSRegularExpressionDotMatchesLineSeparators set docName to getFrontmostMarkdownDocName() of me if docName = false then return set newName to repFileNameExtension(docName, ".pdf") of me set newPath to (POSIX path of (path to desktop)) & newName set dRes to deleteItemAt(newPath) of me –前回実行時にデスクトップに残った同名のPDFを削除する –Markdownのソースを元ファイルから直接読み出す set docSourcePath to getFrontmostMarkdownFullPath() of me set aStr to (read (docSourcePath as alias) as «class utf8») –getHeader List set aList to retHeaders(aStr) of me –Export Markdown to PDF (desktop folder) macDownForceSave() of me set tList to textInPDFinEachPage(newPath) of me set pCount to 1 set midashOchiList to {} repeat with i in tList set j to (contents of i) as string repeat with ii in aList set jj to (contents of second item of ii) as string –set jj2 to replaceText(jj, "(", "(") of me –set jj3 to replaceText(jj2, ")", ")") of me if (j ends with jj) then set the end of midashOchiList to {pCount, jj} end if end repeat set pCount to pCount + 1 end repeat return midashOchiList on retHeaders(aCon) set tList to {} set regStr to "^#{1,6}[^#]*?$" set headerList to my findPattern:regStr inString:aCon repeat with i in headerList set j to contents of i set regStr2 to "^#{1,6}[^#]*?" set headerLevel to length of first item of (my findPattern:regStr2 inString:j) set tmpHeader1 to text (headerLevel + 1) thru -1 in j –ヘッダーの前後から空白文字をトリミング set tmpHeader2 to trimWhiteSpaceFromHeadAndTail(tmpHeader1) of me –ヘッダー部でPDF書き出ししたときに全角文字が半角文字に置換されてしまうケースに対処 set tmpHeader3 to replaceText(tmpHeader2, "(", "(") of me set tmpHeader4 to replaceText(tmpHeader3, ")", ")") of me set the end of tList to {headerLevel, tmpHeader4} end repeat return tList end retHeaders on findPattern:thePattern inString:theString set theOptions to ((NSRegularExpressionDotMatchesLineSeparators) as integer) + ((NSRegularExpressionAnchorsMatchLines) as integer) set theRegEx to NSRegularExpression’s regularExpressionWithPattern:thePattern options:theOptions |error|:(missing value) set theFinds to theRegEx’s matchesInString:theString options:0 range:{location:0, |length|:length of theString} set theFinds to theFinds as list — so we can loop through set theResult to {} — we will add to this set theNSString to NSString’s stringWithString:theString repeat with i from 1 to count of items of theFinds set theRange to (item i of theFinds)’s range() set end of theResult to (theNSString’s substringWithRange:theRange) as string end repeat return theResult end findPattern:inString: –指定文字列の前後から空白をトリミング on trimWhiteSpaceFromHeadAndTail(aStr as string) set aString to NSString’s stringWithString:aStr set bString to aString’s stringByTrimmingCharactersInSet:(NSCharacterSet’s whitespaceAndNewlineCharacterSet()) return bString as list of string or string –as anything end trimWhiteSpaceFromHeadAndTail –ファイル名の拡張子を置換する on repFileNameExtension(origName, newExt) set aName to current application’s NSString’s stringWithString:origName set theExtension to aName’s pathExtension() if (theExtension as string) is not equal to "" then set thePathNoExt to aName’s stringByDeletingPathExtension() set newName to (thePathNoExt’s stringByAppendingString:newExt) else set newName to (aName’s stringByAppendingString:newExt) end if return newName as string end repFileNameExtension on textInPDFinEachPage(thePath) set aList to {} set anNSURL to (current application’s |NSURL|’s fileURLWithPath:thePath) set theDoc to current application’s PDFDocument’s alloc()’s initWithURL:anNSURL set theCount to theDoc’s pageCount() as integer repeat with i from 1 to theCount set thePage to (theDoc’s pageAtIndex:(i – 1)) set curStr to (thePage’s |string|()) set curStr2 to curStr’s decomposedStringWithCanonicalMapping() –Normalize Text with NFC set targString to string id 13 & string id 10 & string id 32 & string id 65532 –Object Replacement Character set bStr to (curStr2’s stringByTrimmingCharactersInSet:(current application’s NSCharacterSet’s characterSetWithCharactersInString:targString)) set the end of aList to (bStr as string) end repeat return aList end textInPDFinEachPage –注意!! ここでGUI Scriptingを使用。バージョンが変わったときにメニュー階層などの変更があったら書き換え on macDownForceSave() activate application "MacDown" tell application "System Events" tell process "MacDown" — File > Export > PDF click menu item 2 of menu 1 of menu item 14 of menu 1 of menu bar item 3 of menu bar 1 –Go to Desktop Folder keystroke "d" using {command down} –Save Button on Sheet click button 1 of sheet 1 of window 1 end tell end tell end macDownForceSave on getFrontmostMarkdownDocName() tell application "MacDown" set dList to every document set dCount to count every item of dList if dCount is not equal to 1 then display notification "Markdown document is not only one." return false end if tell document 1 set docName to name end tell return docName end tell end getFrontmostMarkdownDocName on getFrontmostMarkdownFullPath() tell application "MacDown" tell document 1 set aProp to properties end tell end tell set aPath to (file of aProp) end getFrontmostMarkdownFullPath –任意のデータから特定の文字列を置換 on replaceText(origData, origText, repText) set curDelim to AppleScript’s text item delimiters set AppleScript’s text item delimiters to {origText} set origData to text items of origData set AppleScript’s text item delimiters to {repText} set origData to origData as text set AppleScript’s text item delimiters to curDelim –set b to origData as text return origData end replaceText –指定のPOSIX pathのファイルを強制削除(あってもなくてもいい) on deleteItemAt(aPOSIXpath) set theNSFileManager to current application’s NSFileManager’s defaultManager() set theResult to theNSFileManager’s removeItemAtPath:(aPOSIXpath) |error|:(missing value) return (theResult as integer = 1) as boolean end deleteItemAt |
multi page tiffを読み込んで、PDFにする v2
| AppleScript名:multi page tiffを読み込んで、PDFにする v2 |
| — Created 2015-01-01 by Takaaki Naganoya — Modified 2016-04-18 by Takaaki Naganoya — 2016 Piyomaru Software use AppleScript version "2.4" use scripting additions use framework "Foundation" use framework "QuartzCore" use framework "Quartz" use framework "AppKit" property |NSURL| : a reference to current application’s |NSURL| property NSString : a reference to current application’s NSString property PDFPage : a reference to current application’s PDFPage property NSImage : a reference to current application’s NSImage property PDFDocument : a reference to current application’s PDFDocument property NSBitmapImageRep : a reference to current application’s NSBitmapImageRep set a to choose file of type {"public.tiff"} with prompt "Select Multi-page tiff file" –tiff set aRes to convertMultiPageTiffToPDF(a) of me on convertMultiPageTiffToPDF(anAlias) –Make Output Path set b to POSIX path of anAlias set bb to changeExtensionInPath("pdf", b) –OutPath –Read Multi-Page TIFF set aURL to |NSURL|’s fileURLWithPath:b set aImage to NSImage’s alloc()’s initWithContentsOfURL:aURL set aRawimg to aImage’s TIFFRepresentation() set eachTiffPages to (NSBitmapImageRep’s imageRepsWithData:aRawimg) as list –Make Blank PDF set aPDFdoc to PDFDocument’s alloc()’s init() set pageNum to 0 repeat with curPage in eachTiffPages set thisImage to contents of curPage set aImg to (NSImage’s alloc()’s initWithSize:(thisImage’s |size|())) (aImg’s addRepresentation:thisImage) (aPDFdoc’s insertPage:(PDFPage’s alloc()’s initWithImage:aImg) atIndex:pageNum) set pageNum to pageNum + 1 end repeat return (aPDFdoc’s writeToFile:bb) as boolean end convertMultiPageTiffToPDF –ファイルパス(POSIX path)に対して、拡張子のみ付け替える on changeExtensionInPath(extStr as string, aPath as string) set pathString to NSString’s stringWithString:aPath set theExtension to pathString’s pathExtension() set thePathNoExt to pathString’s stringByDeletingPathExtension() set newPath to thePathNoExt’s stringByAppendingPathExtension:extStr return newPath as string end changeExtensionInPath |
ASOCでPDFを回転させて保存 v2
| AppleScript名:ASOCでPDFを回転させて保存 v2 |
| — Created 2015-10-20 by Takaaki Naganoya — Modified 2016-07-01 by Takaaki Naganoya–複数回PDFに回転処理を行った場合の挙動を改善 — 2015 Piyomaru Software use AppleScript version "2.4" use scripting additions use framework "Foundation" use framework "QuartzCore" set aPath to POSIX path of (choose file of type {"com.adobe.pdf"} with prompt "Select PDF") set newFile to POSIX path of (choose file name) set pdfRes to rotatePDFandSaveAt(aPath, newFile, 90) of me –oldPath and newPath have to be a POSIX path, aDegree have to be in {0, 90, 180, 270, 360} on rotatePDFandSaveAt(oldPath as string, newPath as string, aDegree as integer) –Error Check if aDegree is not in {0, 90, 180, 270, 360} then error "Wrong Degree" set aURL to current application’s |NSURL|’s fileURLWithPath:oldPath set aPDFdoc to current application’s PDFDocument’s alloc()’s initWithURL:aURL set pCount to aPDFdoc’s pageCount() –count pages –Make Blank PDF set newPDFdoc to current application’s PDFDocument’s alloc()’s init() –Rotate Each Page repeat with i from 0 to (pCount – 1) set aPage to (aPDFdoc’s pageAtIndex:i) –Set Degree set curDegree to aPage’s |rotation|() –Get Current Degree (aPage’s setRotation:(aDegree + curDegree)) –Set New Degree (newPDFdoc’s insertPage:aPage atIndex:i) end repeat set aRes to newPDFdoc’s writeToFile:newPath return aRes as boolean end rotatePDFandSaveAt |
ASOCでPDFの各種情報を取得する
PDFの各種情報を取得するAppleScriptです。
これまで、GUIアプリケーションを呼び出してPDFの情報を取得していましたが、PDFKitの機能を利用してAppleScript単体で(GUIアプリケーションの機能を呼び出すことなく)処理できるようになりました。
PDF関連は、ほぼたいていの処理をAppleScriptだけで行えています。しいて(自分が)できていないのは、ウォーターマークを埋め込むような処理ぐらいでしょうか。それ以外であれば、たいてい行えます。
| AppleScript名:ASOCでPDFの各種情報を取得する |
| — Created 2015-10-20 by Takaaki Naganoya — 2015 Piyomaru Software use AppleScript version "2.5" use scripting additions use framework "Foundation" use framework "QuartzCore" set aPath to POSIX path of (choose file of type {"com.adobe.pdf"} with prompt "Select PDF") set aURL to current application’s |NSURL|’s fileURLWithPath:aPath set aPDFdoc to current application’s PDFDocument’s alloc()’s initWithURL:aURL set pCount to aPDFdoc’s pageCount() –ページ数 –> 1 set aMajorVersion to aPDFdoc’s majorVersion() –バージョン(メジャーバージョン) –> 1 set aMinorVersion to aPDFdoc’s minorVersion() –バージョン(マイナーバージョン) –> 3 set aRoot to aPDFdoc’s outlineRoot() –> missing value set anAttr to (aPDFdoc’s documentAttributes()) as record –> (NSDictionary) {Creator:"Pages", Producer:"Mac OS X 10.11.1 Quartz PDFContext", ModDate:(NSDate) 2015-10-20 07:45:55 +0000, Title:"testPDF", CreationDate:(NSDate) 2015-10-20 07:45:55 +0000} set aCreator to anAttr’s Creator() –> "Pages" set aProducer to anAttr’s Producer() –> "Mac OS X 10.11.1 Quartz PDFContext" set aTitle to anAttr’s Title() –> "testPDF" set aCreationDate to anAttr’s CreationDate() –PDF作成年月日 –> date "2015年10月20日火曜日 16:45:55" set aModDate to anAttr’s ModDate() –PDF変更年月日 –> date "2015年10月20日火曜日 16:45:55" set anEncF to aPDFdoc’s isEncrypted() –暗号化されている(パスワードが設定されている)か? –> false set anLockF to aPDFdoc’s isLocked() –ロックされているか? –> false set aCopyF to aPDFdoc’s allowsCopying() –テキストのコピーを許可されているか? –> true set aPrintF to aPDFdoc’s allowsPrinting() –印刷を許可されているか? –> true –PDFのサイズを取得する(単位:Point) set aPage to aPDFdoc’s pageAtIndex:0 set aBounds to aPage’s boundsForBox:(current application’s kPDFDisplayBoxMediaBox) set aSize to |size| of aBounds –> {width:595.28, height:841.89} |
連番JPEGファイルを読み込んで連結したPDFを作成(既存のPDFに追加)
| AppleScript名:連番JPEGファイルを読み込んで連結したPDFを作成(既存のPDFに追加) |
| — Created 2016-09-20 by Takaaki Naganoya — 2016 Piyomaru Software use AppleScript version "2.4" use scripting additions use framework "Foundation" use framework "QuartzCore" use framework "Quartz" use framework "AppKit" set aExt to ".jpg" set targAlias to retFrontFinderWindowsTargetIfExits(path to desktop) of me set aFol to choose folder with prompt "追記するJPEG画像ファイルが入っているフォルダを選択" default location targAlias set fList to getFilePathList(aFol, aExt) of me set f2List to my sort1DList:fList ascOrder:true –sort by ascending set newFile to POSIX path of (choose file of type {"com.adobe.pdf"} with prompt "既存のPDFファイルを選択(このPDF末尾に画像を追加)") set newFilePath to current application’s NSString’s stringWithString:newFile set newFileURL to current application’s |NSURL|’s fileURLWithPath:newFile –Get Exsisting PDF’s URL and Use it set aPDFdoc to current application’s PDFDocument’s alloc()’s initWithURL:newFileURL set pageNum to ((aPDFdoc’s pageCount()) as integer) repeat with i in f2List set j to contents of i set aURL to (current application’s |NSURL|’s fileURLWithPath:j) set bImg to (current application’s NSImage’s alloc()’s initWithContentsOfURL:aURL) (aPDFdoc’s insertPage:(current application’s PDFPage’s alloc()’s initWithImage:bImg) atIndex:pageNum) set pageNum to pageNum + 1 end repeat aPDFdoc’s writeToFile:newFilePath –ASOCで指定フォルダのファイルパス一覧取得(拡張子指定つき) on getFilePathList(aFol, aExt) set aPath to current application’s NSString’s stringWithString:(POSIX path of aFol) set aFM to current application’s NSFileManager’s defaultManager() set nameList to (aFM’s contentsOfDirectoryAtPath:aPath |error|:(missing value)) as list set anArray to current application’s NSMutableArray’s alloc()’s init() repeat with i in nameList set j to i as text if (j ends with aExt) and (j does not start with ".") then –exclude invisible files set newPath to (aPath’s stringByAppendingString:j) (anArray’s addObject:newPath) end if end repeat return anArray as list end getFilePathList –1D List(文字)をsort / ascOrderがtrueだと昇順ソート、falseだと降順ソート on sort1DList:theList ascOrder:aBool set aDdesc to current application’s NSSortDescriptor’s sortDescriptorWithKey:"self" ascending:aBool selector:"localizedCaseInsensitiveCompare:" set theArray to current application’s NSArray’s arrayWithArray:theList return (theArray’s sortedArrayUsingDescriptors:{aDdesc}) as list end sort1DList:ascOrder: on retFrontFinderWindowsTargetIfExits(aDefaultLocation) tell application "Finder" set wCount to count every window if wCount ≥ 1 then tell front window set aTarg to target as alias end tell return aTarg else return aDefaultLocation end if end tell end retFrontFinderWindowsTargetIfExits |
{kind=link}
連番JPEGファイルを読み込んで連結したPDFを作成(新規作成)
| AppleScript名:連番JPEGファイルを読み込んで連結したPDFを作成(新規作成) |
| — Created 2016-09-20 by Takaaki Naganoya — 2016 Piyomaru Software use AppleScript version "2.4" use scripting additions use framework "Foundation" use framework "QuartzCore" use framework "Quartz" use framework "AppKit" set aExt to ".jpg" set aFol to choose folder set fList to getFilePathList(aFol, aExt) of me set f2List to my sort1DList:fList ascOrder:true –sort by ascending set newFile to POSIX path of (choose file name with prompt "新規PDFファイルの名称を選択") set newFilePath to current application’s NSString’s stringWithString:newFile –Make Blank PDF set aPDFdoc to current application’s PDFDocument’s alloc()’s init() set pageNum to 0 repeat with i in f2List set j to contents of i set aURL to (current application’s |NSURL|’s fileURLWithPath:j) set bImg to (current application’s NSImage’s alloc()’s initWithContentsOfURL:aURL) (aPDFdoc’s insertPage:(current application’s PDFPage’s alloc()’s initWithImage:bImg) atIndex:pageNum) set pageNum to pageNum + 1 end repeat aPDFdoc’s writeToFile:newFilePath –ASOCで指定フォルダのファイルパス一覧取得(拡張子指定つき) on getFilePathList(aFol, aExt) set aPath to current application’s NSString’s stringWithString:(POSIX path of aFol) set aFM to current application’s NSFileManager’s defaultManager() set nameList to (aFM’s contentsOfDirectoryAtPath:aPath |error|:(missing value)) as list set anArray to current application’s NSMutableArray’s alloc()’s init() repeat with i in nameList set j to i as text if (j ends with aExt) and (j does not start with ".") then –exclude invisible files set newPath to (aPath’s stringByAppendingString:j) (anArray’s addObject:newPath) end if end repeat return anArray as list end getFilePathList –1D List(文字)をsort / ascOrderがtrueだと昇順ソート、falseだと降順ソート on sort1DList:theList ascOrder:aBool set aDdesc to current application’s NSSortDescriptor’s sortDescriptorWithKey:"self" ascending:aBool selector:"localizedCaseInsensitiveCompare:" set theArray to current application’s NSArray’s arrayWithArray:theList return (theArray’s sortedArrayUsingDescriptors:{aDdesc}) as list end sort1DList:ascOrder: |
{kind=link}
PDFから本文テキストを抽出して配列にストアして文字列検索
| AppleScript名:PDFから本文テキストを抽出して配列にストアして文字列検索 |
| — Created 2017-06-18 by Takaaki Naganoya — 2017 Piyomaru Software use AppleScript version "2.4" use scripting additions use framework "Foundation" use framework "Quartz" property textCache : missing value property aList : {} –検索対象の語群 set sList to {"notification", "Cocoa"} –considering case set thePath to POSIX path of (choose file of type {"com.adobe.pdf"}) –PDFのテキスト内容をあらかじめページごとに読み取って、検索用のテキストキャッシュを作成 set anNSURL to (current application’s |NSURL|’s fileURLWithPath:thePath) set theDoc to current application’s PDFDocument’s alloc()’s initWithURL:anNSURL set theCount to theDoc’s pageCount() as integer set textCache to current application’s NSMutableArray’s new() repeat with i from 0 to (theCount – 1) set aPage to (theDoc’s pageAtIndex:i) set tmpStr to (aPage’s |string|()) (textCache’s addObject:{pageIndex:i + 1, pageString:tmpStr}) end repeat –主にテキストキャッシュを対象にキーワード検索 repeat with s in sList –❶部分一致で抽出 set bRes to ((my filterRecListByLabel1(textCache, "pageString contains ’" & s & "’"))’s pageIndex) as list –❷、❶のページ単位のテキスト検索で見つからなかった場合(ページ間でまたがっている場合など) if bRes = {} then set bRes to {} set theSels to (theDoc’s findString:s withOptions:0) repeat with aSel in theSels set thePage to (aSel’s pages()’s objectAtIndex:0)’s label() set curPage to (thePage as integer) if curPage is not in bRes then set the end of bRes to curPage end if end repeat end if set the end of aList to bRes end repeat return aList –リストに入れたレコードを、指定の属性ラベルの値で抽出 on filterRecListByLabel1(aRecList as list, aPredicate as string) set aArray to current application’s NSArray’s arrayWithArray:aRecList set aPredicate to current application’s NSPredicate’s predicateWithFormat:aPredicate set filteredArray to aArray’s filteredArrayUsingPredicate:aPredicate return filteredArray end filterRecListByLabel1 |
PDFの本文テキスト内容からリンクURLを抽出する
| AppleScript名:本文テキスト内容からリンクURLを抽出する |
| — Created 2017-08-12 by Takaaki Naganoya — 2017 Piyomaru Software use AppleScript version "2.5" use scripting additions use framework "Foundation" use framework "Quartz" use BPlus : script "BridgePlus" –https://www.macosxautomation.com/applescript/apps/Script_Libs.html#BridgePlus property NSString : a reference to current application’s NSString property NSCharacterSet : a reference to current application’s NSCharacterSet property NSRegularExpression : a reference to current application’s NSRegularExpression property NSRegularExpressionAnchorsMatchLines : a reference to current application’s NSRegularExpressionAnchorsMatchLines property NSRegularExpressionDotMatchesLineSeparators : a reference to current application’s NSRegularExpressionDotMatchesLineSeparators script spdPDF property foundURLs : {} property aList : {} property outList : {} end script load framework set (foundURLs of spdPDF) to {} set theFile to POSIX path of (choose file of type "com.adobe.pdf") set (aList of spdPDF) to textInPDFinEachPage(theFile) of me set pCounter to 1 repeat with i in (aList of spdPDF) set aURL1 to extractLinksFromNaturalText(i as string) of me set aURL2 to (current application’s SMSForder’s arrayByDeletingBlanksIn:((aURL1) as list)) set tmpOut to {} repeat with ii in aURL2 set aURL to (ii’s absoluteString()) as string if aURL begins with "http://piyocast.com/as/" then set the end of tmpOut to aURL end if end repeat if tmpOut is not equal to {} then set (outList of spdPDF) to (outList of spdPDF) & tmpOut end if end repeat set outStr to retArrowText(outList of spdPDF, return) of me on textInPDFinEachPage(thePath) script textStorage property aList : {} end script set (aList of textStorage) to {} set anNSURL to (current application’s |NSURL|’s fileURLWithPath:thePath) set theDoc to current application’s PDFDocument’s alloc()’s initWithURL:anNSURL set theCount to theDoc’s pageCount() as integer repeat with i from 1 to theCount set thePage to (theDoc’s pageAtIndex:(i – 1)) set curStr to (thePage’s |string|()) set curStr2 to curStr’s decomposedStringWithCanonicalMapping() –Normalize Text with NFC set targString to string id 13 & string id 10 & string id 32 & string id 65532 –Object Replacement Character set bStr to (curStr2’s stringByTrimmingCharactersInSet:(current application’s NSCharacterSet’s characterSetWithCharactersInString:targString)) set the end of (aList of textStorage) to (bStr as string) end repeat return contents of (aList of textStorage) end textInPDFinEachPage on extractLinksFromNaturalText(aString) set anNSString to current application’s NSString’s stringWithString:aString set {theDetector, theError} to current application’s NSDataDetector’s dataDetectorWithTypes:(current application’s NSTextCheckingTypeLink) |error|:(reference) set theMatches to theDetector’s matchesInString:anNSString options:0 range:{0, anNSString’s |length|()} set theResults to theMatches’s valueForKey:"URL" return theResults as list end extractLinksFromNaturalText –リストを指定デリミタをはさんでテキスト化 on retStrFromArrayWithDelimiter(aList, aDelim) set anArray to current application’s NSArray’s arrayWithArray:aList set aRes to anArray’s componentsJoinedByString:aDelim return aRes as text end retStrFromArrayWithDelimiter on retArrowText(aList, aDelim) –自分のASでよく使うハンドラ名称なので、同じものを用意 return my retStrFromArrayWithDelimiter(aList, aDelim) end retArrowText |
ASOCでPDFをページごとに分解する v3
| AppleScript名:ASOCでPDFをページごとに分解する v3 |
| — Created 2014-12-26 by Takaaki Naganoya — Modified 2015-09-26 by Takaaki Naganoya — Modified 2015-10-01 by Takaaki Naganoya — 2015 Piyomaru Software use AppleScript version "2.4" use scripting additions use framework "Foundation" –use framework "Quartz" use framework "QuartzCore" set aHFSPath to (choose file of type {"com.adobe.pdf"} with prompt "ページごとに分解するPDFを指定してください") set aPOSIX to POSIX path of aHFSPath set aURL to (current application’s |NSURL|’s fileURLWithPath:aPOSIX) set aPOSIXpath to POSIX path of aHFSPath —書き出し先パスをPOSIX pathで用意しておく(あとで加工) set aPDFdoc to current application’s PDFDocument’s alloc()’s initWithURL:aURL set pCount to aPDFdoc’s pageCount() –PDFをページごとに分割してファイル書き出し repeat with i from 0 to (pCount – 1) set thisPage to (aPDFdoc’s pageAtIndex:(i)) set thisDoc to (current application’s PDFDocument’s alloc()’s initWithData:(thisPage’s dataRepresentation())) set outPath to addString_beforeExtensionIn_("_" & (i + 1) as string, aPOSIXpath) (thisDoc’s writeToFile:outPath) –書き出し end repeat –ファイルパス(POSIX path)に対して、文字列(枝番)を追加。拡張子はそのまま on addString:extraString beforeExtensionIn:aPath set pathString to current application’s NSString’s stringWithString:aPath set theExtension to pathString’s pathExtension() set thePathNoExt to pathString’s stringByDeletingPathExtension() set newPath to (thePathNoExt’s stringByAppendingString:extraString)’s stringByAppendingPathExtension:theExtension return newPath as string end addString:beforeExtensionIn: |
ASOCでPDFをページごとに分解してJPEGで保存する v3
| AppleScript名:ASOCでPDFをページごとに分解してJPEGで保存する v3 |
| — Created 2014-12-26 by Takaaki Naganoya — Modified 2015-09-26 by Takaaki Naganoya — Modified 2015-10-01 by Takaaki Naganoya — Modified 2016-07-27 by Takaaki Naganoya–Save each PDF page as jpeg — Modified 2016-07-27 by Takaaki Naganoya–Zero padding function, Consider Retina Env — 2016 Piyomaru Software # http://piyocast.com/as/archives/4176 use AppleScript version "2.4" use scripting additions use framework "Foundation" use framework "Quartz" use framework "QuartzCore" use framework "AppKit" set aHFSPath to (choose file of type {"com.adobe.pdf"} with prompt "ページごとに分解するPDFを指定してください") set aPOSIX to POSIX path of aHFSPath set aURL to (current application’s |NSURL|’s fileURLWithPath:aPOSIX) set aPOSIXpath to POSIX path of aHFSPath —書き出し先パスをPOSIX pathで用意しておく(あとで加工) set aPDFdoc to current application’s PDFDocument’s alloc()’s initWithURL:aURL set pCount to aPDFdoc’s pageCount() set compFactor to 1.0 –1.0 — 0.0 = max jpeg compression, 1.0 = none –Detect Retina Environment set retinaF to current application’s NSScreen’s mainScreen()’s backingScaleFactor() if retinaF = 1.0 then set aScale to 2.0 –Non Retina Env else set aScale to 1.0 –Retina Env end if –PDFをページごとに分割してJPEGでファイル書き出し repeat with i from 0 to (pCount – 1) –Pick Up a PDF page as an image set thisPage to (aPDFdoc’s pageAtIndex:(i)) set thisDoc to (current application’s NSImage’s alloc()’s initWithData:(thisPage’s dataRepresentation())) if thisDoc = missing value then error "Error in getting imagerep from PDF in page:" & (i as string) –Resize Image set pointSize to thisDoc’s |size|() set newSize to current application’s NSMakeSize((pointSize’s width) * aScale, (pointSize’s height) * aScale) set newImage to (current application’s NSImage’s alloc()’s initWithSize:newSize) newImage’s lockFocus() (thisDoc’s setSize:newSize) (current application’s NSGraphicsContext’s currentContext()’s setImageInterpolation:(current application’s NSImageInterpolationHigh)) (thisDoc’s drawAtPoint:(current application’s NSZeroPoint) fromRect:(current application’s CGRectMake(0, 0, newSize’s width, newSize’s height)) operation:(current application’s NSCompositeCopy) fraction:1.0) newImage’s unlockFocus() –Save Image as JPEG set theData to newImage’s TIFFRepresentation() set newRep to (current application’s NSBitmapImageRep’s imageRepWithData:theData) set targData to (newRep’s representationUsingType:(current application’s NSJPEGFileType) |properties|:{NSImageCompressionFactor:compFactor, NSImageProgressive:false}) set zText to retZeroPaddingText((i + 1), 4) of me set outPath to addString_beforeExtensionIn_addingExtension_("_" & zText, aPOSIXpath, "jpg") (targData’s writeToFile:outPath atomically:true) –書き出し end repeat –ファイルパス(POSIX path)に対して、文字列(枝番)を追加。任意の拡張子を追加 on addString:extraString beforeExtensionIn:aPath addingExtension:aExt set pathString to current application’s NSString’s stringWithString:aPath set theExtension to pathString’s pathExtension() set thePathNoExt to pathString’s stringByDeletingPathExtension() set newPath to (thePathNoExt’s stringByAppendingString:extraString)’s stringByAppendingPathExtension:aExt return newPath as string end addString:beforeExtensionIn:addingExtension: on retZeroPaddingText(aNum as integer, aDigitNum as integer) if aNum > (((10 ^ aDigitNum) as integer) – 1) then return "" –Range Check set aFormatter to current application’s NSNumberFormatter’s alloc()’s init() aFormatter’s setUsesGroupingSeparator:false aFormatter’s setAllowsFloats:false aFormatter’s setMaximumIntegerDigits:aDigitNum aFormatter’s setMinimumIntegerDigits:aDigitNum aFormatter’s setPaddingCharacter:"0" set aStr to aFormatter’s stringFromNumber:(current application’s NSNumber’s numberWithFloat:aNum) return aStr as string end retZeroPaddingText |
ASOCで指定PDFのページ数をかぞえる v2
| AppleScript名:ASOCで指定PDFのページ数をかぞえる v2 |
| use AppleScript version "2.4" use scripting additions use framework "Foundation" use framework "AppKit" use framework "QuartzCore" set aFile to choose file of type {"com.adobe.pdf"} set pCount to my pdfPageCount:aFile –指定PDFのページ数をかぞえる(10.9対応。普通にPDFpageから取得) –返り値:PDFファイルのページ数(整数値) on pdfPageCount:aFile set aFile to POSIX path of aFile set theURL to current application’s |NSURL|’s fileURLWithPath:aFile set aPDFdoc to current application’s PDFDocument’s alloc()’s initWithURL:theURL set aRes to aPDFdoc’s pageCount() return aRes as integer end pdfPageCount: |
Numbers書類からPDF書き出し v2
| AppleScript名:Numbers書類からPDF書き出し v2 |
| — Created 2017-03-28 by Takaaki Naganoya — 2017 Piyomaru Software use AppleScript version "2.4" use scripting additions use framework "Foundation" set tmpPath to (path to desktop) as string set aRes to exportNumbersDocToPDF(tmpPath) –Pages書類からPDF書き出し on exportNumbersDocToPDF(targFolderPath as string) tell application "Numbers" set dCount to count every document if dCount = 0 then return false end if set aPath to file of document 1 end tell set curPath to (current application’s NSString’s stringWithString:(POSIX path of aPath))’s lastPathComponent()’s stringByDeletingPathExtension()’s stringByAppendingString:".pdf" set outPath to (targFolderPath & curPath) tell application "Numbers" set anOpt to {class:export options, image quality:Best} export document 1 to file outPath as PDF with properties anOpt end tell end exportNumbersDocToPDF |
