指定URLの初出の指定タグ要素を抽出するAppleScriptです。
たまたま、戦場の絆Wikiから各種データを自動で抽出するAppleScriptを書いたときについでに作った、各ページのh2タグで囲まれた機種名を取り出す処理部分です。
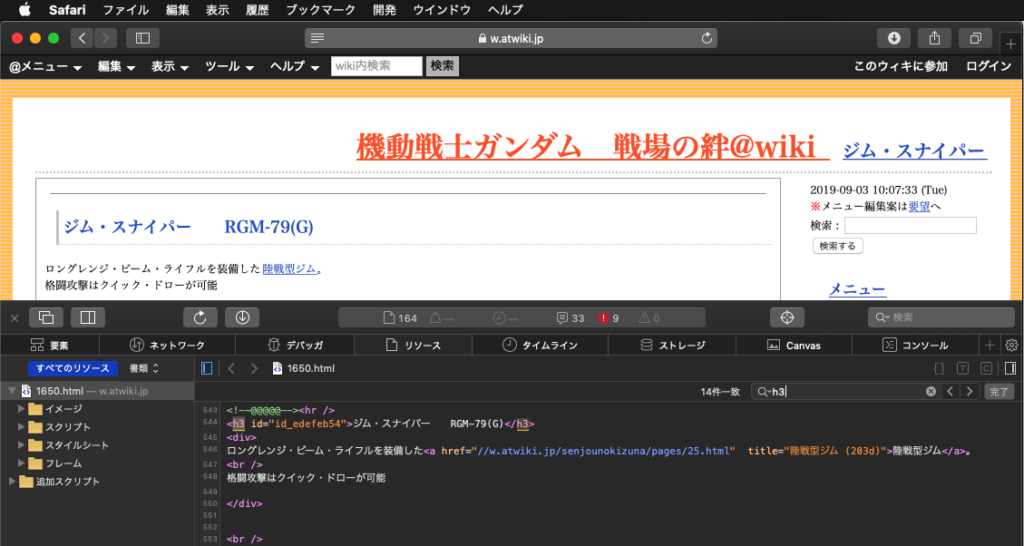
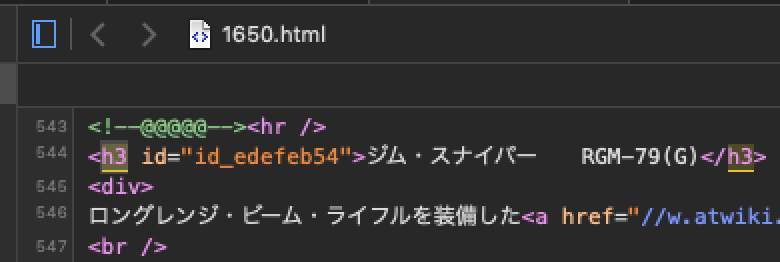
▲このデータだけ機種名がh3タグでマークされていて、例外を吸収するために汎用性を高めたのが本ルーチン
Webサイトからのデータ取り出しは割と重要な技術です。それを容易に可能にするHTMLReaderのようなFrameworkは、とても重要なパーツといえます。HTMLReaderがなければ、こんな簡単に処理することはできなかったでしょう(この些細な処理を、ではなくやりたい処理全体に対しての評価)。
# WebスクレイピングはScripter必須の技術なので、Safari/ChromeでDOMアクセス派や正規表現でソースから抽出派、XMLとして解釈してXPathでアクセスする派などいろいろありそうですが、自分はHTMLReaderを使って楽をしてデータを取り出す派 といえます
特定のURL上のHTMLの特定のタグ要素のデータを抜き出すという処理であり、かならずしもどのサイトでも万能に処理できるというわけでもありません。ただ、Wikiのような管理プログラムでコンテンツを生成しているサイトから各種データを抜き出すのは、生成されるHTMLの規則性が高くて例外が少ないため、割と簡単です。
HTMLReaderをAppleScriptから呼び出し、表データを2D Listとして解釈するなど、データ取り出しが簡単にできるようになったことは意義深いと思われます。
macOS 10.13まではスクリプトエディタ/Script Debugger上でScriptを直接実行できます。macOS 10.14以降ではSIPを解除するか、Script Debugger上で実行するか、本記事に添付したようなアプレット(バンドル内にFramework同梱)を実行する必要があります。
HTMLReaderについては、Frameworkにするよりもアプリケーション化してsdefをつけて、AppleEvent経由で呼び出す専用のバックグラウンドアプリケーションにすることも考えるべきかもしれません。ただ、すべての機能についてsdefをかぶせるためには、「こういうパターンで処理すると便利」という例をみつけてまとめる必要があります。つまり、sdefをかぶせると返り値はAppleScript的なデータに限定されるため、何らかの処理が完結した状態にする必要があります。
–> Download tagElementPicker.zip (Code Signed executable Applet)
–> Download HTMLReader.framework (To ~/Library/Frameworks)
Webコンテンツのダウンロードは、本ルーチンではcurlコマンドで実装していますが、いろいろ試してみたところ現時点で暫定的にこれがベストという判断を行っています。
もともと、macOS 10.7でURL Access Scriptingが廃止になったため、Webアクセスのための代替手段を確保することはScritperの間では優先順位の高い調査項目でした。
curlコマンドはその代替手段の中でも最有力ではあったものの、macOS 10.10以降のAppleScript処理系自体のScripting Bridge対応にともない、NSURLConnectionを用いたアクセスも試してきました。同期処理できて、Blocks構文の記述が必須ではないため、実装のための難易度がCocoa系のサービスでは一番低かったからです。
ただし、NSURLConnection自体がDeprecated扱いになり、後継のNSURLSessionを用いた処理を模索。いろいろ書いているうちに、処理内容がapplescript-stdlibのWebモジュールと酷似した内容になってきた(もともと同ライブラリではNSURLSessionを用いていたため)ので、この機能のためだけにapplescript-stdlibを組み込んで使ってみたりもしました。
しかし、applescript-stdlibのWebモジュールは連続して呼び出すと処理が止まるという代物であり、実際のプログラムに組み込んで使うのは「不可能」でした。1つのURLを処理するには問題はないものの、数百個のURLを処理させると止まることを確認しています。おまけに処理本体にも自分自身のsdefを用いた記述を行っているためメンテナンス性が最悪で、中身をいじくることは(自分には)無理です。
# applescript-stdlibのWebモジュールではUserAgent名がサイト側の想定しているものに該当せずアクセスを拒否されたのか、Webモジュール側の内部処理がまずいのかまでは原因追求できていません。連続処理を行うと止まるという症状を確認しているだけです
NSURLSessionによる処理については、applescript-stdlibのWebモジュールを参考にしつつもう少し書き慣れる必要がある一方で、いろいろモジュール単位で差し替えて試行錯誤したところ、curlコマンドは遅くなったり処理が止まったりすることもなく利用できています。
それでも、curlコマンド以外の選択肢を用意しておくことは重要であるため、NSURLSessionも引き続き追いかけておきたいところです。
| AppleScript名:指定URLのMS名を取得する v2.scptd |
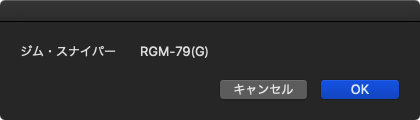
| — Created 2019-09-02 by Takaaki Naganoya — 2019 Piyomaru Software use AppleScript version "2.4" use scripting additions use framework "Foundation" use framework "HTMLReader" –https://github.com/nolanw/HTMLReader property NSString : a reference to current application’s NSString property HTMLDocument : a reference to current application’s HTMLDocument property NSMutableArray : a reference to current application’s NSMutableArray set aURL to "https://w.atwiki.jp/senjounokizuna/pages/1650.html" set aRes to getTitleFromAURL(aURL) of me –> "ジム・スナイパー RGM-79(G)" on getTitleFromAURL(aURL) set aData to (do shell script "curl " & aURL) set aHTML to current application’s HTMLDocument’s documentWithString:(aData as string) –Levelの高いHeader Tagから順次低い方にサーチして返す repeat with i from 2 to 7 by 1 set aHeaderTag to "h" & i as string set eList to (aHTML’s nodesMatchingSelector:aHeaderTag) if (eList as list) is not equal to {} then return (eList’s firstObject()’s textContent()) as string end if end repeat error "Header is missing" end getTitleFromAURL |