




オープンソースのMecabラッパー「MecabCocoa.framework」を呼び出して、日本語の文字列を形態素解析するAppleScriptです。
単語(形態素)に分割する形態素解析については、動作しているものの、
partOfSpeechType:品詞
originalForm:原形
といったあたりの、重要な情報がまともに返ってこないので、単語分割やよみがなの機能しか動作していないように見えるのですが、、、、
| AppleScript名:MecabCocoaで形態素解析.scptd |
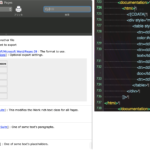
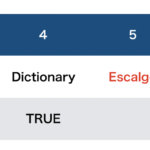
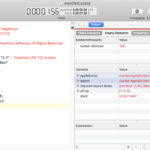
| — – Created by: Takaaki Naganoya – Created on: 2018/11/13 — – Copyright © 2018 Piyomaru Software, All Rights Reserved — use AppleScript version "2.4" — Yosemite (10.10) or later use framework "Foundation" use framework "MecabCocoa" –https://github.com/shinjukunian/MecabCocoa use scripting additions set aStr to "私の名前は長野谷です。" set tokenArray to (current application’s MecabTokenizer’s alloc()’s parseToNodeWithString:aStr withDictionary:2) set tList to (tokenArray’s surface) as list –> {"私", "の", "名前", "は", "長野", "谷", "です", "。"} set fList to (tokenArray’s features) as list –> {{"watakushi"}, missing value, {"namae"}, missing value, {"nagano"}, {"tani"}, missing value, missing value} set psList to (tokenArray’s partOfSpeechType) as list –> {100, 100, 100, 100, 100, 100, 100, 100} –おかしい? |
(Visited 114 times, 1 visits today)